
今天再为大家分享几组近期发布的人工智能工具:
1. EVI 2
本周Hume推出了EVI 2基础模型。EVI 2能够以亚秒级的响应时间与用户快速交谈,理解用户的语音语调,或者改变语速和说话的风格。EVI 2同时具备多语言能力,能够模仿多种性格、口音和说话风格。该模型专注于情感智能,是一种专门针对情商训练的模型。
2. Domoai新功能
本周Domoai宣布推出upscale功能,可以增强图像和视频的分辨率。该工具可以将图像或者视频的分辨率提升到2K和4K,支持最大50兆的文件上传,视频最长支持60秒的持续时长。登录到DomoAI就可以尝试该功能,用户可以切换图像或视频增强,且可以设置增强的倍数。目前,免费用户仅能增强10秒钟以内的视频,大家可以尝试。
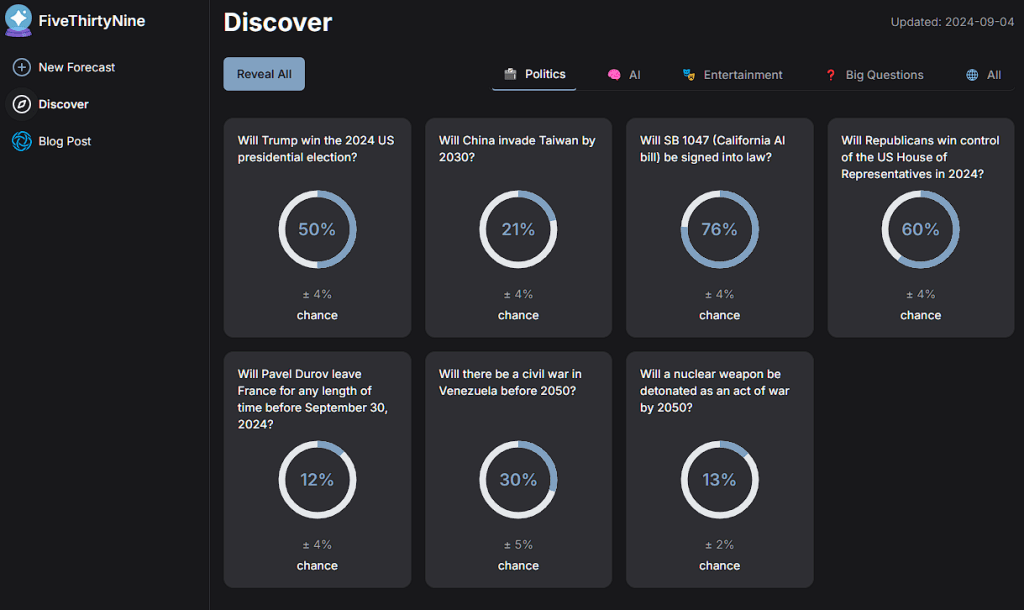
这是一个AI预测模型,能够预判未来发生的事件,准确率可达87%以上。该模型首先会搜集资料,基于事实给出理由,并根据强度进行评分,最后得出结论。例如咨询特朗普在本次大选中的胜算,five thirty nine会首先查询权威新闻媒体,列举出一些事实,然后提出各种可能性,并得出自己的结论,根据显示来看特朗普赢得大选的几率是50%。如果参考推特的内容,则会得出更加准确的结论。该工具由大语言模型驱动,用户也可以手动切换GPT4、GPT4o模型,大家可以尝试。
本周Adobe宣布即将发布Firefly video model,Adobe Firefly video将会支持视频编辑功能、多样化的运镜模式和图像转视频功能。此外,用户还可以选择视频的比例以及FPS的数值。从官方提供的演示可以看出,Firefly video model能够根据文本提示生成带有流畅动作以及逼真光影效果的视频。在提示词中添加和镜头相关的提示,也可以实现不同的运镜效果。无论在提示词理解力、3D渲染,还是画质清晰度方面,Firefly video都有不错的表现。
5. Vchitect 2.0
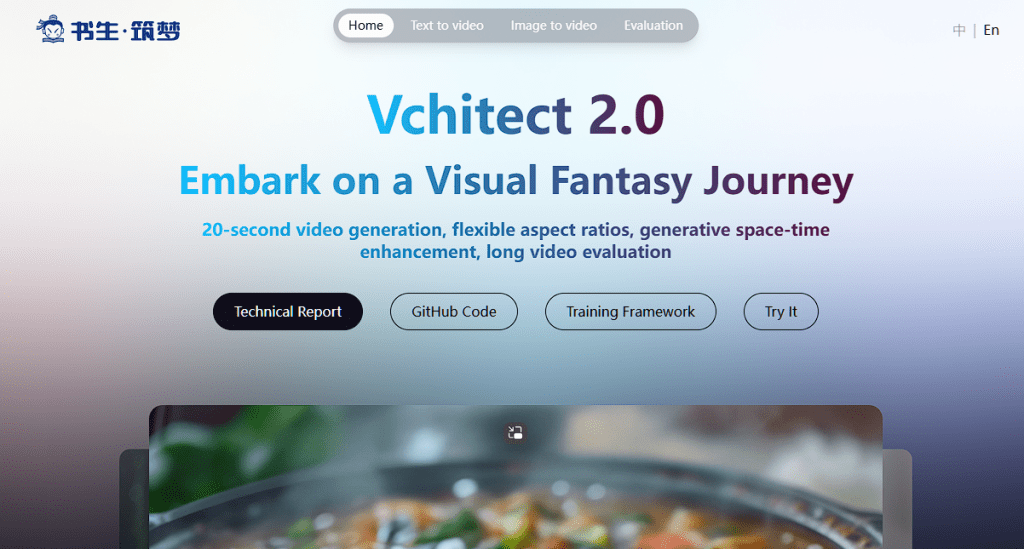
本周上海人工智能实验室发布了Vchitect 2.0视频生成模型。Vchitect 2.0支持文字、视频、图像转视频功能,且支持不同比例的视频输出。在和主流视频生成模型的对比中,Vchitect 2.0的多项测试得分也不落下风。Vchitect 2.0模型具备20亿参数,可以生成720分辨率、持续5-20秒钟的视频。通过官方提供的样本可以看出,该模型在色彩饱和度、运动流畅度以及画面真实度方面还无法和主流模型相比。Vchitect 2.0会在近期开放Demo测试,大家可以关注。
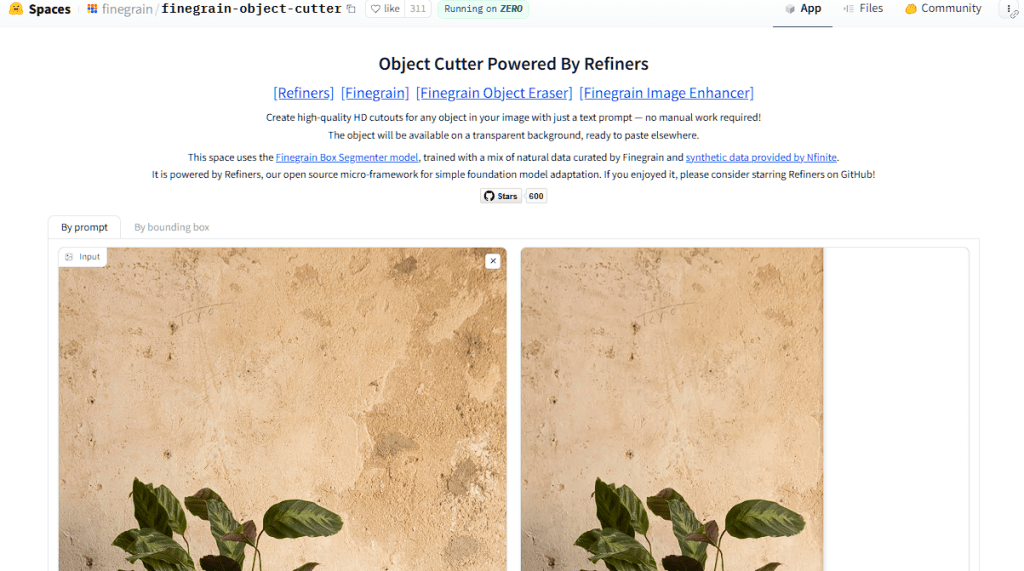
这是一个开源的背景移除工具,可以手动选择或者根据文本提示词保留图像中特定的物体,并完成背景移除。点击视频下方链接就可以在huggingface体验该工具。例如,我们可以指定保留图像中的花盆,并移除背景和其他要素。在下方的对话框中输入cup关键字,也可以仅保留杯子。
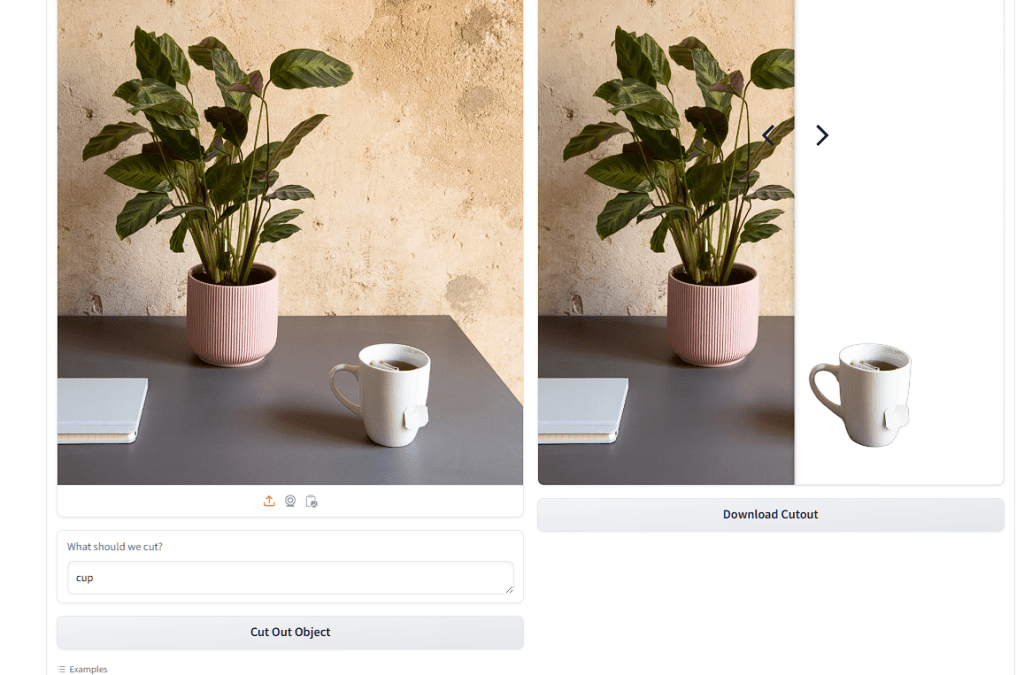
大家可以尝试。
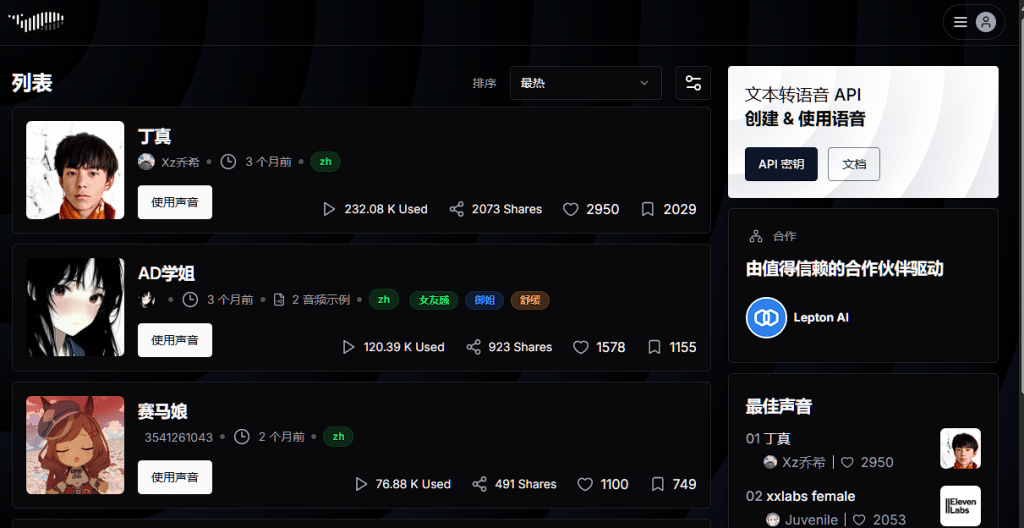
本周开源TTS模型fish speech推出了1.4版本,将会支持更多语音、实时语音克隆,以及超低延迟的语音输出。点击视频下方链接就可以在线尝试最新版本。用户可以使用平台的热门音色合成音频,或者克隆自己的语音。上传30秒以上的音频即可完成音色克隆。