分享一下近期的人工智能新闻:
这是由西湖大学推出的文本转语音模型,由超过10万小时的中英文数据进行训练。它可以实现中英文混合语音播报的效果,或者带有语气词的语音播报。chatTTS生成原理是,从高斯特噪声中采样,得到一个固定长度的声音,最后作为额外的信息输入到网络。此外,chat TTS还支持微调,模拟不同人物的音色。目前该模型的相关细节还没有发布。
2. GPT4o新玩法
GPT4o有了新玩法,也就是根据一份PDF文档,自动生成复杂的Figma UI设计。
GPT4o可以读取项目需求文档,并结合Figma在几分钟内完成UI设计。由于具备强大的视觉和逻辑分析能力,GPT4o已经可以独立完成一些项目的开发。
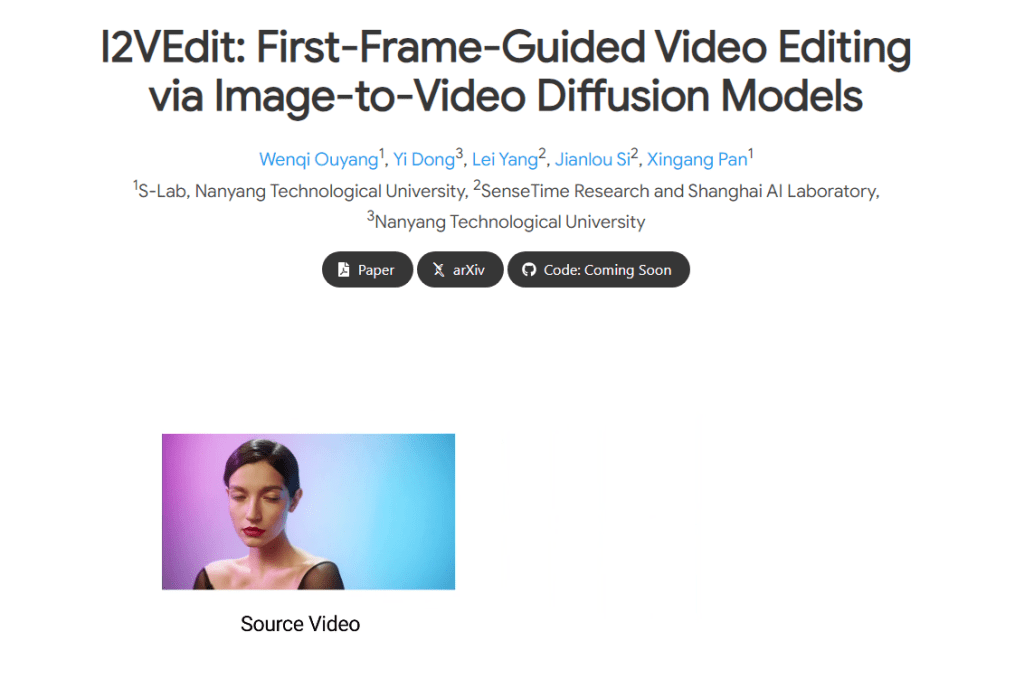
这是一个通过扩散模型引导的视频编辑工具。通过预训练模型,把参考图效果扩展到完整视频,只需对视频的第一帧进行编辑,就可以生成连续的画面。该工具可用于合成虚拟类视频。使用风格转换模型对图像进行编辑,即可生成对应的短视频。该工具还支持人物和物体替换,输出新的内容。
4. Sign LLM
这是全球第一个通过文字描述生成手语视频的多语言模型。将输入的文本提示转化为相应的手语视频。Sinllm可以生成包括美国、德国、中国在内的8种不同手语。该项目引入了名为prompt to sign的多语言手语数据集,并基于此数据集开发了多种手语生成模型。论文地址:https://arxiv.org/abs/2405.10718
5. OpenSora 1.1
本周,开元视频生成模型OpenSora 1.1发布。在视频生成质量和时长方面,有了显著提升。1.1模型能够生成最长21秒的视频。OpenSora 1.1优化了视频架构,提高了性能和推理效率,生成视频的质量和长度都得到了提升。这是在huggingface项目地址:Open Sora Plan V1.1.0 – a Hugging Face Space by LanguageBind
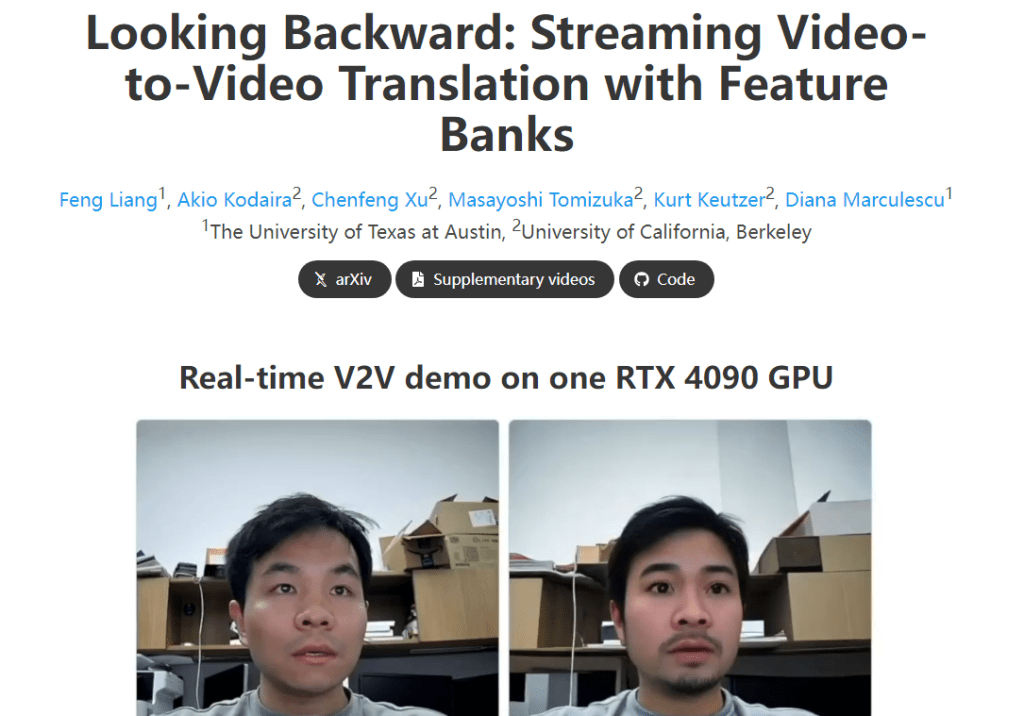
6. Stream v2v
这是一个比较有趣的视频直播换脸扩散模型,可以通过文本提示更换主播的面容。例如,输入”马斯克”就可以完成实时换脸;输入”扎克伯格”,也能实现对应的效果,可以达到实时视频转视频的效果,处理帧速率达到20FPS。Stream v2v使用了流媒体的方式处理,可以实现无限帧的生成。Stream v2v的特点是适应性强、效率高,可与图像扩散模型无缝集成,输出不同风格的人物形象。例如,你可以将自己的形象转换为卡通风格或者油画风格。目前该项目已经开源,可以尝试在本地部署该模型。