
几乎从事电脑相关工作的同学无不听取过Deepseek的大名,自然很多人私信我究竟该如何在本地部署这个优秀的国产模型,下面我些一个无代码的操作流程,即使小白也能够在本地离线部署deepseek R1模型。
为什么我们需要本地部署Deepseek呢?对于模型来说,当我们与AI交流的过程中,它肯定会根据我们上传云端数据进行,这显而易见无法保证我们的个人隐私。本地部署大模型利用本地资源能够更快的进行调用和交互,从而提高工作效率。
说来说去,最主要的原因是因为:
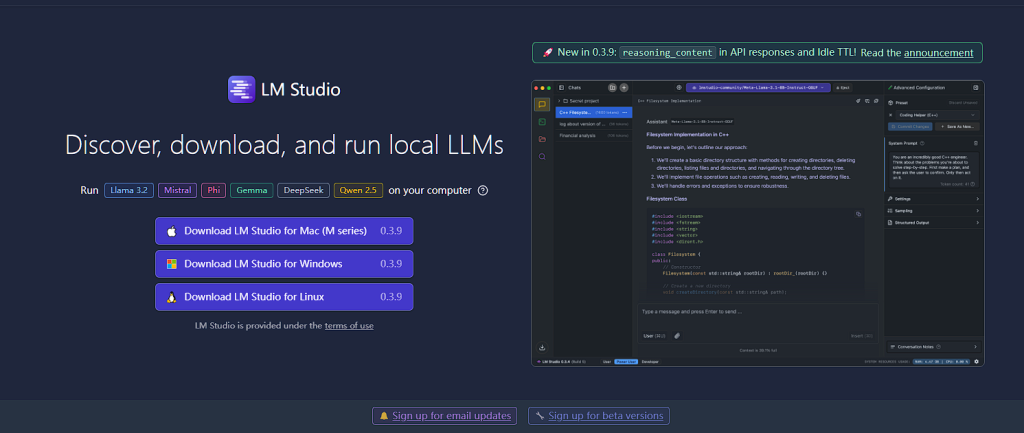
以下是在 LM Studio 上部署 DeepSeek R1 模型的具体操作步骤:
步骤 1:安装 LM Studio
- 访问 LM Studio 官网:https://lmstudio.ai/
- 根据你的操作系统(Windows/macOS/Linux)下载对应版本的 LM Studio。
- 安装并启动 LM Studio。
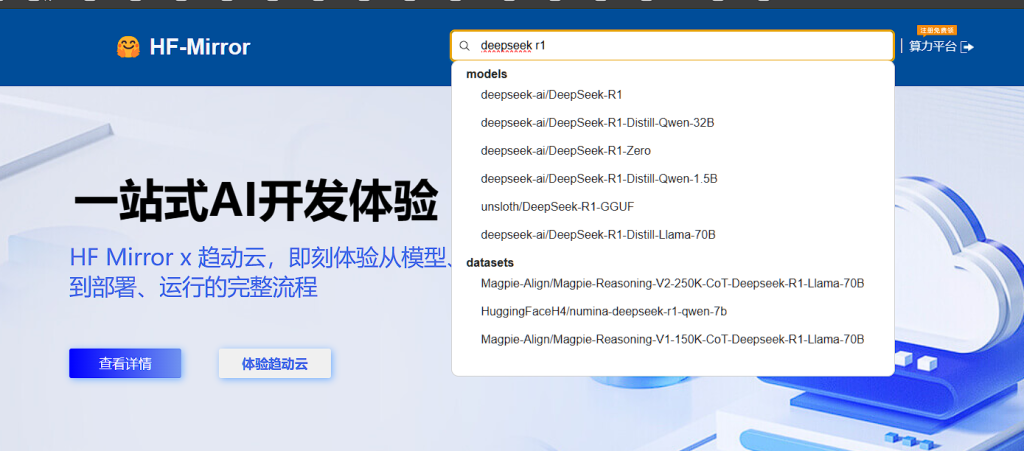
步骤 2:获取 DeepSeek R1 模型文件
- 确认模型格式:
LM Studio 支持 GGUF 格式的模型文件(如deepseek-r1.Q4_K_M.gguf)。确保你下载的模型已转换为 GGUF 格式。 - 下载模型:
- 访问 Hugging Face Hub 或其他模型仓库(如 TheBloke 的 GGUF 转换仓库)。
- 搜索
DeepSeek-R1-GGUF或类似关键词,找到对应的 GGUF 文件并下载。(国内建议使用:HF-Mirror)
- 如果官方未提供 GGUF 格式,可能需要自行转换(需使用
llama.cpp转换工具,但需技术基础)。 - 其实我非常建议使用LM studio时候尝试关闭联网功能,确保信息的本地安全,相关教程见:LM Studio windows系统断网教程,通过防火墙禁止联网。
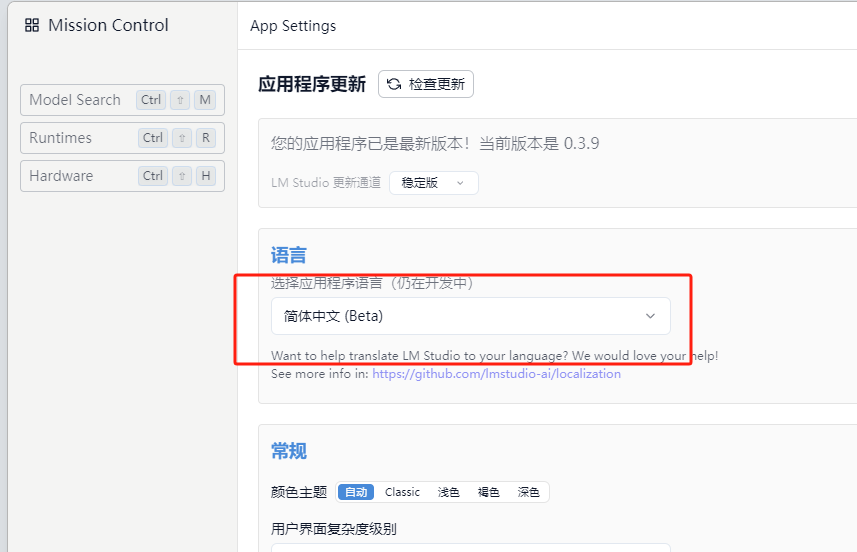
步骤 3:在 LM Studio 中加载模型
打开 LM Studio,首先可以点击右下角设置按钮将语言设定为【简体中文】:
- 启动软件后,进入主界面,点击左侧导航栏的 “Local Server”。
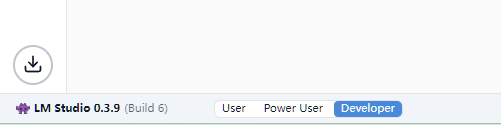
注意:需要在【developer】或者【power user】状态下才能选择模型:
- 确保本地服务器已启动(状态显示为 “运行”)。
加载模型:
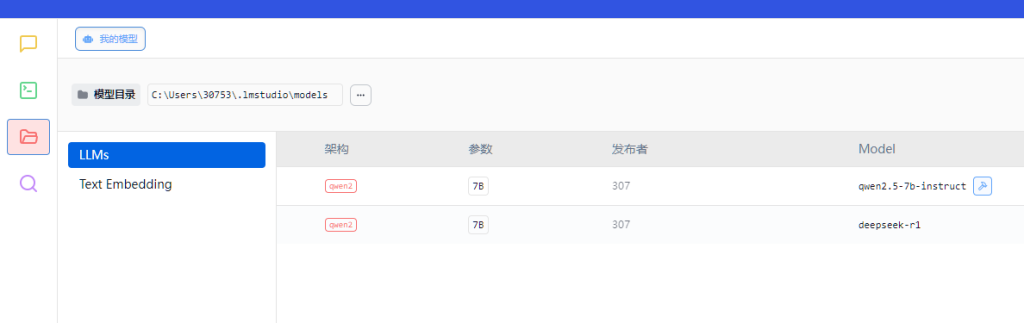
- 点击左侧导航栏的 “模型“图标(如下所示)。
- 点击的 “模型目录”,将下载好的
deepseek-r1-*.gguf文件放入弹出的文件夹中。
- 返回 LM Studio,刷新模型列表,选择
DeepSeek-R1的 GGUF 文件。
步骤 4:配置模型参数
- 在模型加载页面,调整以下参数以优化性能:
- GPU Offload(如有 NVIDIA/AMD 显卡):启用 GPU 加速。
- Context Length:根据显存调整上下文长度(如 2048)。
- Temperature 和 Top-P:根据需求调整生成结果的随机性。
步骤 5:测试模型
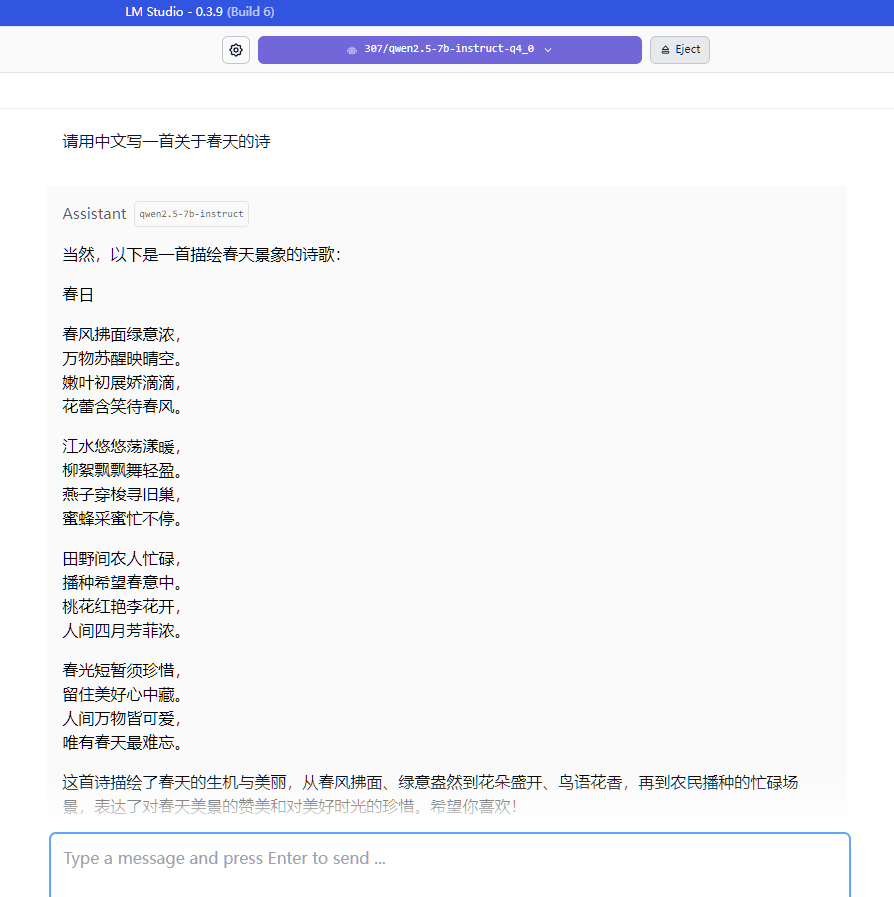
- 点击左侧导航栏的 “聊天” 进入对话界面。
- 输入测试提示词(例如:
请用中文写一首关于春天的诗)。
常见问题解决
- 模型无法加载:
- 确认模型为 GGUF 格式。
- 确保文件路径无中文或特殊字符。
- 更新 LM Studio 到最新版本。
- 性能不足:
- 降低量化等级(如从
Q5_K_M改用Q4_K_M)。 - 减少上下文长度(Context Length)。
- 关闭其他占用显存的程序。
- 找不到 GGUF 文件:
- 在 Hugging Face 搜索
deepseek-r1 GGUF,或联系开发者获取适配版本。
注意事项
- DeepSeek R1 可能需要较大的内存和显存(如 7B 模型需至少 8GB 显存)。
- 首次加载模型时会自动生成索引,耗时较长,请耐心等待。