
原文:ComfyUI秒出图-SDXL-Turbo – 知乎 (zhihu.com)
SDXL-Turbo模型介绍(原文直译)

SDXL-Turbo 是一种快速文本到图像生成模型,可在单次网络评估中根据文本提示合成逼真的图像。实时演示请点击:http://clipdrop.co/stable-diffusion-turbo
SDXL-Turbo is a fast generative text-to-image model that can synthesize photorealistic images from a text prompt in a single network evaluation. A real-time demo is available here: http://clipdrop.co/stable-diffusion-turbo
模型描述
SDXL-Turbo 是 SDXL 1.0 的提炼版本,经过训练可用于实时合成。SDXL-Turbo 基于一种名为 “对抗扩散提炼”(Adversarial Diffusion Distillation,简称 ADD)的新型训练方法(参见技术报告),可在 1 到 4 个步骤内以高图像质量对大规模基础图像扩散模型进行采样。这种方法使用分数蒸馏来利用大规模现成的图像扩散模型作为教师信号,并将其与对抗损失相结合,以确保即使在 1 或 2 步采样的低步骤机制下也能获得高图像保真度。
SDXL-Turbo is a distilled version of SDXL 1.0, trained for real-time synthesis. SDXL-Turbo is based on a novel training method called Adversarial Diffusion Distillation (ADD) (see the technical report), which allows sampling large-scale foundational image diffusion models in 1 to 4 steps at high image quality. This approach uses score distillation to leverage large-scale off-the-shelf image diffusion models as a teacher signal and combines this with an adversarial loss to ensure high image fidelity even in the low-step regime of one or two sampling steps.
模型来源
出于研究目的,我们推荐使用我们的生成模型 Github 存储库 (https://github.com/Stability-AI/generative-models),它实现了最流行的扩散框架(包括训练和推理)。
For research purposes, we recommend our generative-models Github repository (https://github.com/Stability-AI/generative-models), which implements the most popular diffusion frameworks (both training and inference).
资源库:https://github.com/Stability-AI/generative-models 论文: https://stability.ai/research/adversarial-diffusion-distillation 演示:http://clipdrop.co/stable-diffusion-turbo
评估
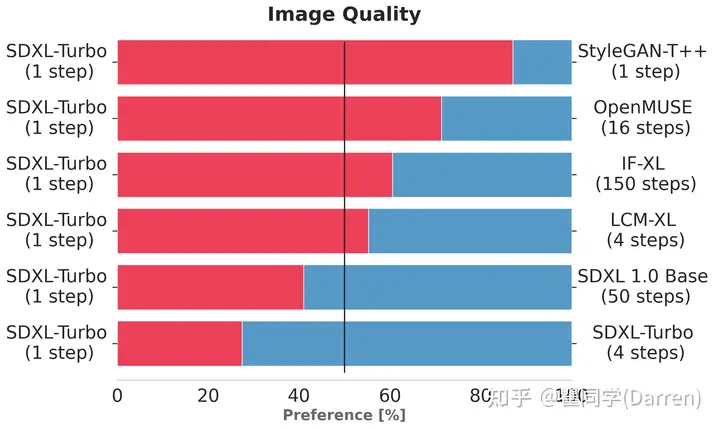
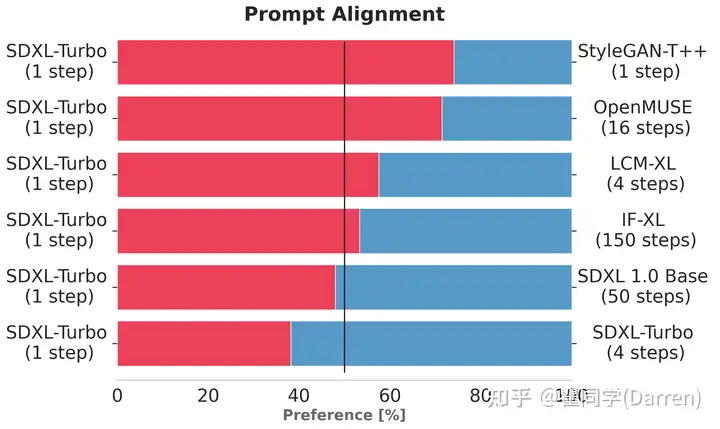
上述图表评估了用户对 SDXL-Turbo 的偏好程度,而不是对其他单步和多步型号的偏好程度。在图像质量和提示跟踪方面,单步评估的 SDXL-Turbo 比四步(或更少)评估的 LCM-XL 更受人类投票者的青睐。此外,我们还发现,SDXL-Turbo 采用四个步骤可进一步提高性能。有关用户研究的详细信息,请参阅研究论文。
The charts above evaluate user preference for SDXL-Turbo over other single- and multi-step models. SDXL-Turbo evaluated at a single step is preferred by human voters in terms of image quality and prompt following over LCM-XL evaluated at four (or fewer) steps. In addition, we see that using four steps for SDXL-Turbo further improves performance. For details on the user study, we refer to the research paper.
直接使用
该模型仅用于研究目的。可能的研究领域和任务包括 – 生成模型研究。 – 研究生成模型的实时应用。 – 研究实时生成模型的影响。 – 安全部署有可能生成有害内容的模型。 – 探索和了解生成模型的局限性和偏差。 – 艺术作品的生成以及在设计和其他艺术过程中的应用。 – 教育或创造性工具中的应用。 除外用途说明如下。
The model is intended for research purposes only. Possible research areas and tasks include – Research on generative models. – Research on real-time applications of generative models. – Research on the impact of real-time generative models. – Safe deployment of models which have the potential to generate harmful content. – Probing and understanding the limitations and biases of generative models. – Generation of artworks and use in design and other artistic processes. – Applications in educational or creative tools. Excluded uses are described below.
Python使用diffusers
pip install diffusers transformers accelerate --upgrade文本到图像: SDXL-Turbo 不使用 guidance_scale 或 negative_prompt,我们使用 guidance_scale=0.0 将其禁用。模型最好生成 512×512 尺寸的图像,但更大尺寸的图像也可以使用。一个步骤就足以生成高质量的图像。
SDXL-Turbo does not make use of guidance_scale or negative_prompt, we disable it with guidance_scale=0.0. Preferably, the model generates images of size 512×512 but higher image sizes work as well. A single step is enough to generate high quality images.
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
pipe.to("cuda")
prompt = "一只穿着精致意大利牧师袍的小浣熊的电影般镜头。"
image = pipe(prompt=prompt, num_inference_steps=1, guidance_scale=0.0).images[0]图像到图像: 使用 SDXL-Turbo 生成图像到图像时,请确保 num_inference_steps * strength 大于或等于 1。 图像到图像流水线将以 int(num_inference_steps * strength) 步长运行,例如,在下面的示例中,0.5 * 2.0 = 1 步。使用 SDXL-Turbo 生成图像到图像时,请确保 num_inference_steps * strength 大于或等于 1。 图像到图像流水线将以 int(num_inference_steps * strength) 步长运行,例如,在下面的示例中,0.5 * 2.0 = 1 步。
When using SDXL-Turbo for image-to-image generation, make sure that num_inference_steps * strength is larger or equal to 1. The image-to-image pipeline will run for int(num_inference_steps * strength) steps, e.g. 0.5 * 2.0 = 1 step in our example below.
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import load_image
pipe = AutoPipelineForImage2Image.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/cat.png").resize((512, 512))
prompt = "猫巫师,甘道夫,魔戒,详细,奇幻,可爱,迷人,皮克斯,迪士尼,8k"
image = pipe(prompt, image=init_image, num_inference_steps=2, strength=0.5, guidance_scale=0.0).images[0]超出范围的使用 该模型未经过培训,不能作为人物或事件的真实表现,因此使用该模型生成此类内容超出了该模型的能力范围。请勿以违反 Stability AI 可接受使用政策的方式使用该模型。
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model. The model should not be used in any way that violates Stability AI’s Acceptable Use Policy.
限制
- 生成的图像具有固定分辨率(512×512像素),模型无法实现完美的照片逼真效果。
- 模型无法渲染可辨认的文本。
- 生成的人脸和人物可能不够准确。
- 模型的自编码部分是有损的。
limitations
- The quality and prompt alignment is lower than that of SDXL-Turbo.
- The generated images are of a fixed resolution (512×512 pix), and the model does not achieve perfect photorealism.
- The model cannot render legible text.
- Faces and people in general may not be generated properly.
- The autoencoding part of the model is lossy.
建议 该模型仅用于研究目的。
The model is intended for research purposes only.
ComyfyUI安装和使用
已安装过comfyUI的请更新版本,此模型需要使用最新的ComfyUI版本,下载如下资源完成后解压即可使用。
- 官网下载地址:https://github.com/comfyanonymous/ComfyUI/releases/download/latest/ComfyUI_windows_portable_nvidia_cu121_or_cpu.7z
- 百度云盘链接: https://pan.baidu.com/s/1rQ3J2rCh9zsjxUxJ4LDmlA?pwd=n2i7 提取码:n2i7 (2023.12.01更新)
安装模型
模型下载地址如下:
- 官网下载: https://huggingface.co/stabilityai/sdxl-turbo/tree/main
- 夸克网盘: https://pan.quark.cn/s/85712b7f8ff7 提取码:ariq
下载完成后将模型存放在F:\ComfyUI_windows_portable_nightly_pytorch\ComfyUI\models\checkpoints 下
启动ComfyUI
根据平台启动,如果是英伟达的显卡选run_nvidia_gpu.bat 如果没有独显使用 run_cpu.bat。
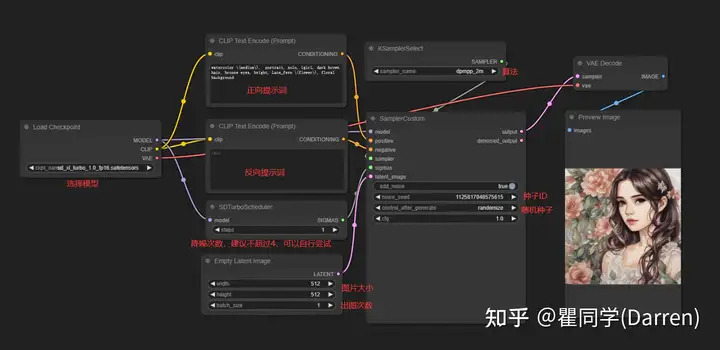
工作流介绍
工作流下载地址: https://pan.baidu.com/s/1GDfOgxii4WDZtLZHMA0o7A?pwd=e5rf 提取码:e5rf
GPU出图速度
单张出图速度为0.5秒左右笔者的测试显卡是2080ti,提示词的变化和降噪算法可能会影响出图速度。
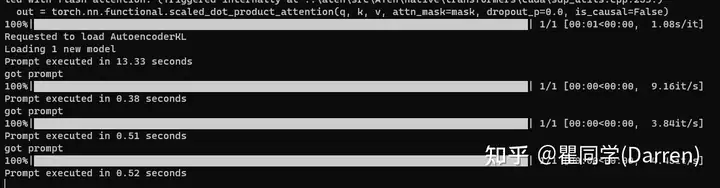
16张图速度为4.9秒。

CPU出图速度
结论是没有GPU的朋友们也可以体验下AI出图,如下使用CPU(i7-11700)计算,20秒以内能出图,虽然相比GPU慢很多相比之前已经进步很多,可以试玩了。
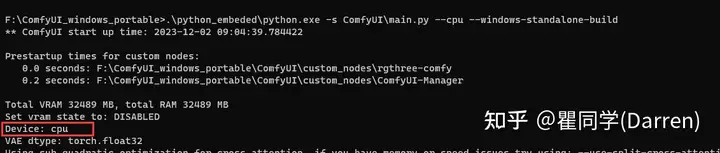
提示词的变化和降噪算法可能会影响出图速度,笔者测试20秒内都能出图。

16张图速度195.95秒

另外为什么SDXL-Turbo能在这么短的时间内出图了? 主要原因还是此模型降噪只需 1-3次就能出图,笔者之前用到的模型降噪一般使用15-30次。
相关链接
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.