
最近,Github发布了一个神奇的AI工具可以将图片+语音生成动态视频的项目—Sadtalker,我们来看看这个项目“
它是由西安交大、腾讯人工智能实验室、蚂蚁团队共同开发的,通过提炼系数和 3D 渲染的面部来从音频中学习准确的面部表情。头部姿势则是通过条件VAE设计PoseVAE,以合成不同风格的头部运动。 最后,将生成的3D运动系数映射到所提人脸渲染的无监督3D关键点空间,并合成最终视频。
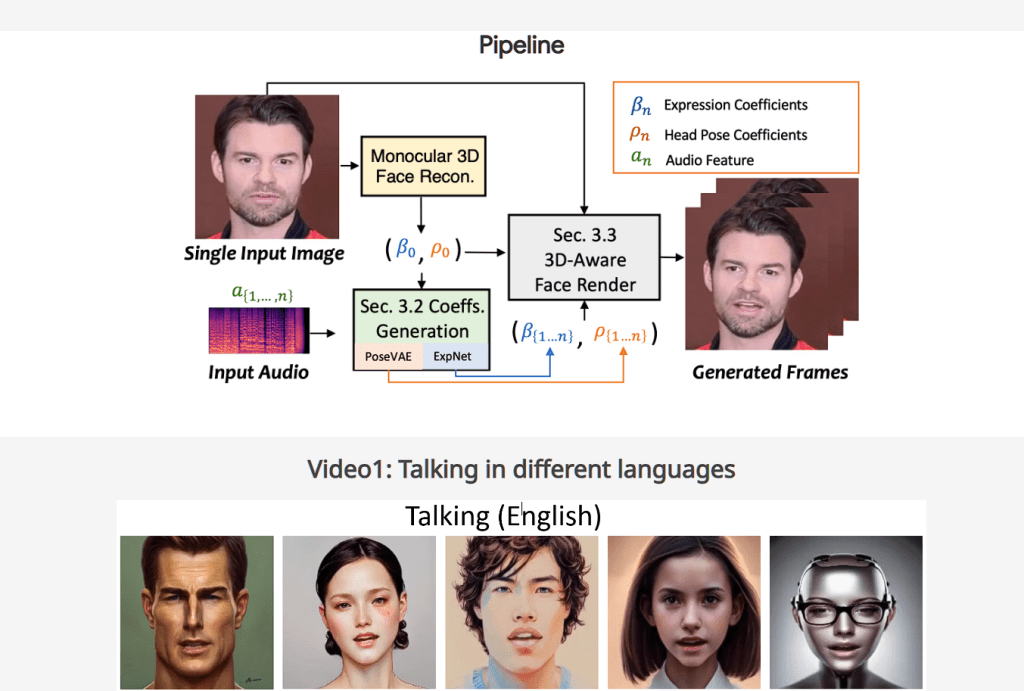
下面是本地部署的流程:
- 安装并Python3.8 并选中“将Python添加到PATH”。
- 手动安装Git或使用Scoop进行安装,在 powershell里执行下面命令:
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUserirmget.scoop.sh | iexscoop install git - 安装ffmpeg ,可以使用本教程或使用scoop进行安装:
scoop install ffmpeg - 通过运行下载 SadTalker 存储库:
git clone https://github.com/Winfredy/SadTalker.git - 下载检查点和 gfpgan 模型。
- 运行start.bat,并且将启动 Gradio 支持的 WebUI 演示。
- 如果出现报错可以尝试下载该文件覆盖到Sadtalker根目录app_sadtalker.zip。
得到下面界面即可表示安装成功:
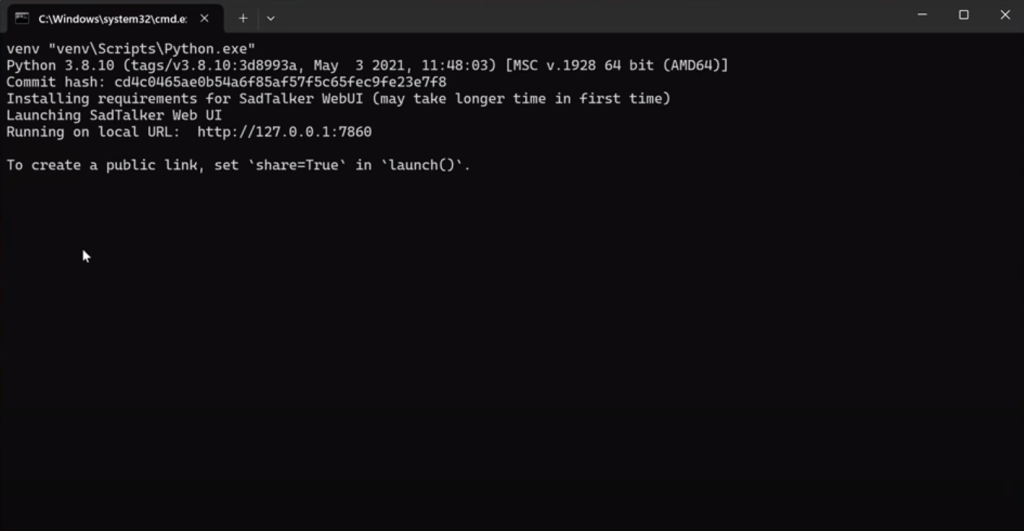
打开http://127.0.0.1:7860,就得到了Web界面,可以调用本地GPU来实现动态视频生成。
如果觉得部署对自己来说有些困难,它还有HuggingFace的链接,直接可以使用:SadTalker – a Hugging Face Space by vinthony
colab地址:stable_diffusion_1_5_video_webui_colab.ipynb – Colab (google.com)
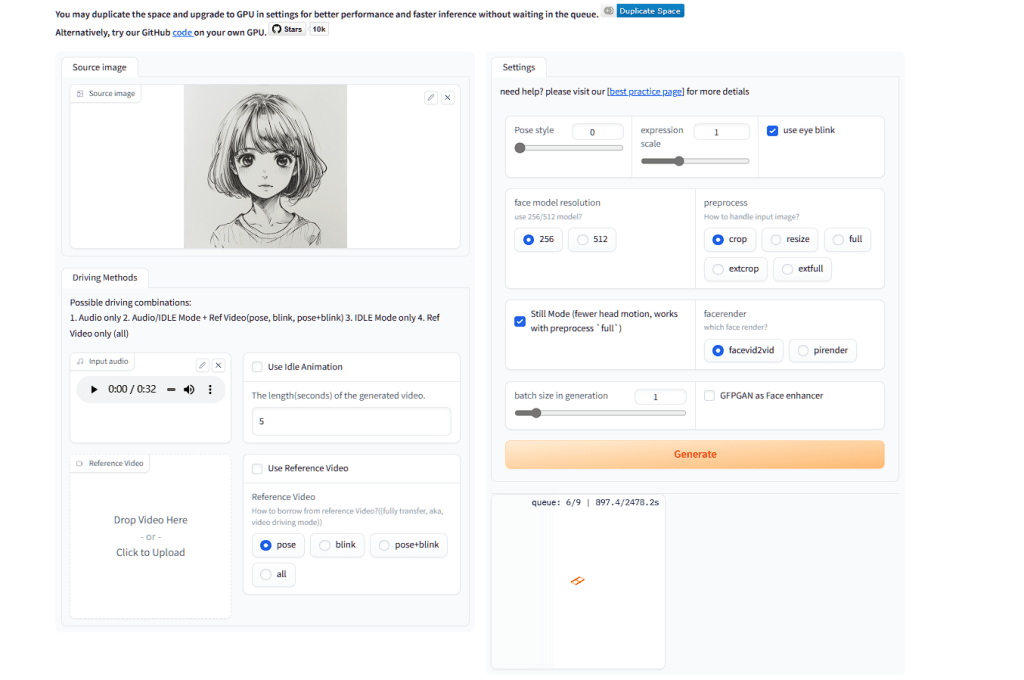
不过,若没有升级GPU,视频生成速度是非常慢的,我这里大概需要40分钟。
感兴趣的同学可以尝试该工具。